
In the beginning of this year I was introduced the ElasticSearch, an impressive piece of software which returns results very quickly especially if you need to fetch humongous amount of data. I was skeptical at first but when we started implementing our first queries there, everything went so smoothly and fast that we thought would be great to have it everywhere instead of using SQL. Everything looked great and well until we got our first issues.
One of those issues was related to version conflicts. ElasticSearch really doesn’t like when you update the same document in your index concurrently. It gives back errors like these:
version conflict, required seqNo [113789], primary term [19]. current document has seqNo [113797] and primary term [19]
When I got those messages I thought how could we work around this issue. After a good Google Search away I got a “solution” where our update requests would require a new argument called conflict=proceed. Without much thinking, adding that seemed to fix our initial conflict issue, until I found out what exactly it was doing.
conflict=proceed basically ignores any documents which conflicts are found and skips updates to them. This is a terrible solution and had to be reverted back to prevent us from not receiving updates from the Pub/Sub system. Reverting it back caused the conflict issue to arise again, but since the Pub/Sub system retried those requests, we were ok for the most part.
Throttling Issues

After half a year of using this approach, I found out that the CPU usage on our ElasticSearch clusters were skyrocketing. At first I thought that we added new listeners to our cluster and I was right, but there was no reason for the CPU to skyrocket from the typical 10% to more than 100% in such a short period of time. Calling _tasks?actions=*&detailed showed me that there were a ton of requests to refresh the indexes. By a ton I really mean a ton. Index refreshing is a very expensive ElasticSearch operation and should be done periodically like every second, not every request (we were receiving hundreds of requests per second at the time). Removing them seemed like a no brainer, and it fixed our issue at the time.
Another thing I did here was to fix an issue in the listener we had setup because it was crashing whenever it had an exception. This would be fine if Kubernetes didn’t have a wait time to restart that increased every time that happened. I couldn’t find a way to fix this behavior at the time, so I just added a try catch to every single listener method and it worked fine, no more crashes.
Throttling Issues II
After just one day of fixing that refresh index issue. I was receiving yet again CPU throttling alerts in my cell phone related to the cluster. It was the same symptom but different cause this time. Turns out that we had a listener setup that wasn’t finding some records in a index. I had to refactor that code to use another column to identify the record. The root cause for this is yet to be found, but using the other column fixed the issue.
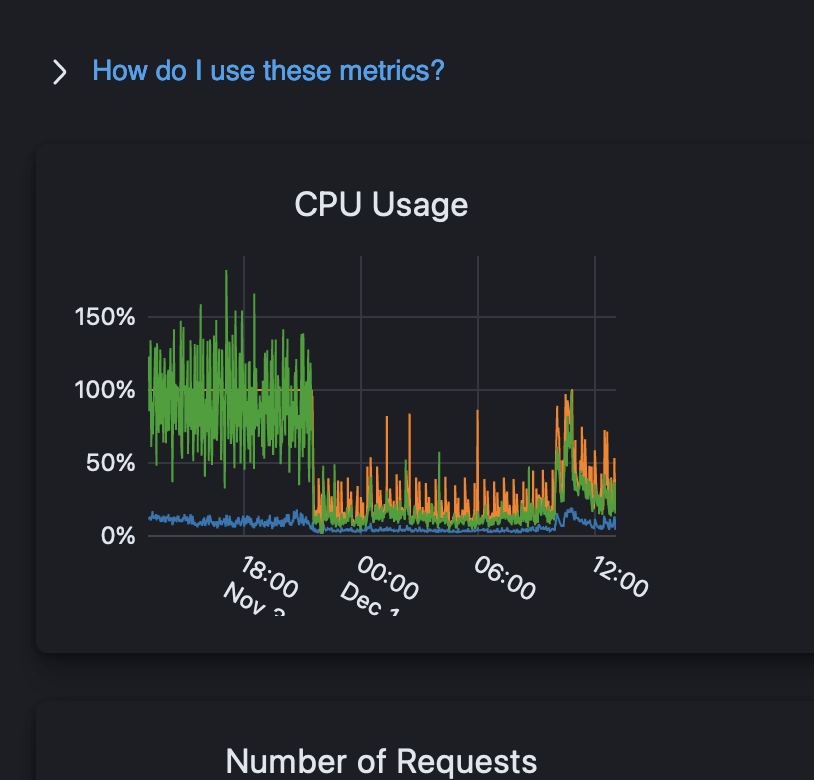
As you can see there, the fix reduced the CPU usage but it was still way too high afterwards, I thought it was fine until…
Throttling Issues III
You guessed it, one day after my column fix, I had yet another CPU Throttling issue happening at the cluster. This was getting old already lol.
Identifying the cause I found out that the listener was being bombarded with the same failed requests from Pub/Sub, by bombarded I mean 400 requests per second. That isn’t fine.
Fixing that is as simple as setting the Retry Policy on Pub/Sub from Retry Immediately to Retry after exponential backoff delay. But that still didn’t fix the root cause of the problem.
The actual fix was to not make two update-by-query requests in the same index sequentially. Remember that initial conflict issue where the same document causes conflicts? Yeah, we were testing ElasticSearch patience by doing that on purpose in the same index and it didn’t like it.
After those two fixes, it seemed that the cluster is way more happy to work now.
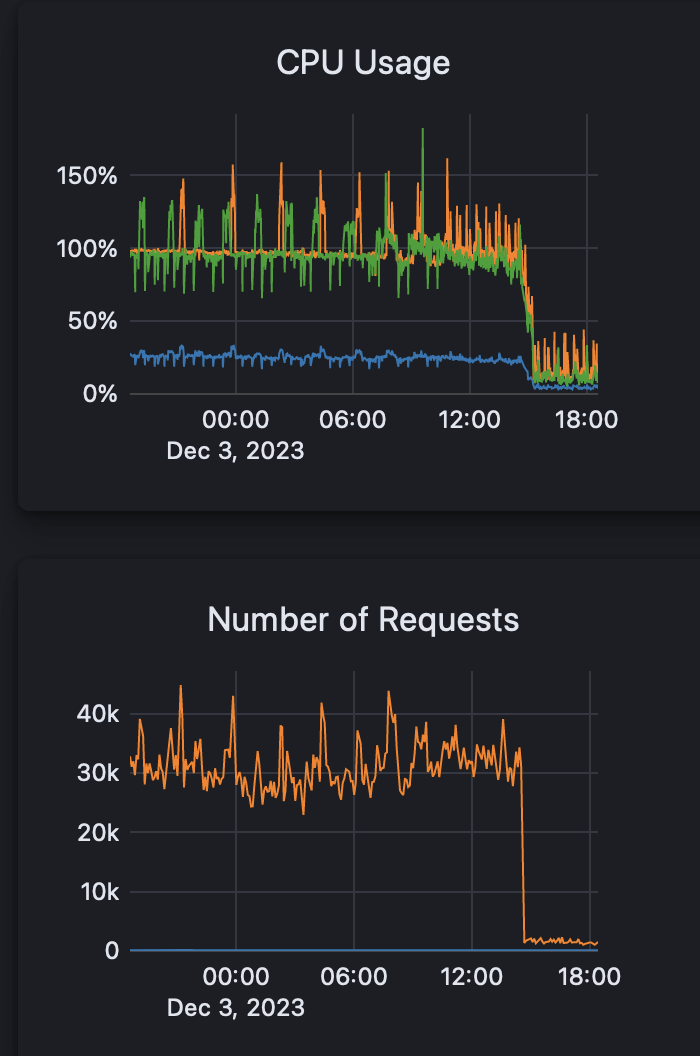
Aftermath
I’m still skeptical if this fix will be enough. Looks like we are receiving a ton of requests from the Pub/Sub that look duplicated and shouldn’t be even updating our indexes. That is something to fix during the week but I am certain it can be fixed easily by just adding an old and new property to the message Pub/Sub sends us and checking if the document in the index needs to be updated. I’ll see.